
「Stable Diffusion Web UI(AUTOMATIC1111)の使い方がよく分からないので詳しく知りたい…」
と困っていませんか?
起動したはいいものの、どうやったらクオリティの高い画像生成をすることが出来るのか
各設定がどういった役割になっているのか全く分からないですよね。
この記事では、Stable Diffusion Web UI(AUTOMATIC1111)の使い方、
各設定項目について詳しく解説しているので
是非記事を参考にしてクオリティの高い画像生成をしてください。
Google ColabでStable Diffusion Web UIの起動・導入のやり方が分からない人は
以下の記事内で詳しく解説しているので読んでみてください。
CivitAIから「Any Lora」と呼ばれるモデルデータも追加しているので
すぐにアニメ風の可愛い画像生成をすることが出来ます。

Checkpointモデルについて

左上にある「Stable Diffusion checkpoint」項目内では
Checkpointモデルのみを選択することが出来ます。
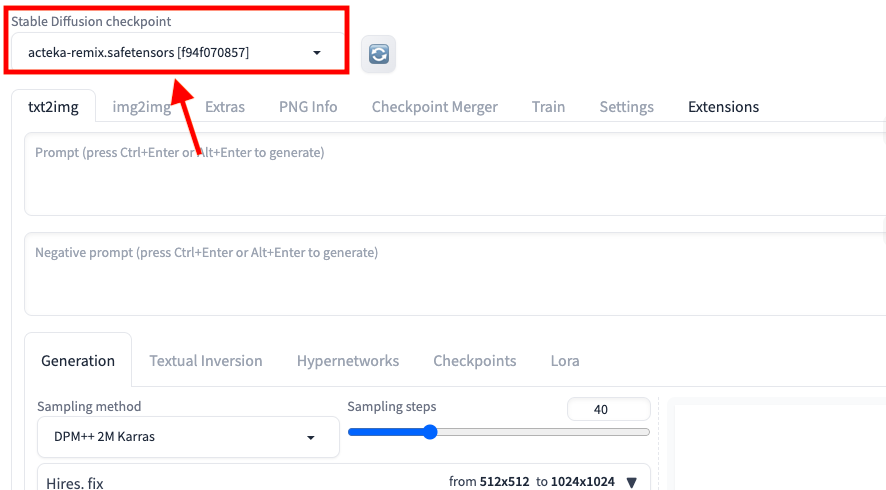
Checkpointモデルは、モデルを配布している「CivitAI」や「Hugging Face」のサイトからダウンロードして導入すると使用することが出来ます。
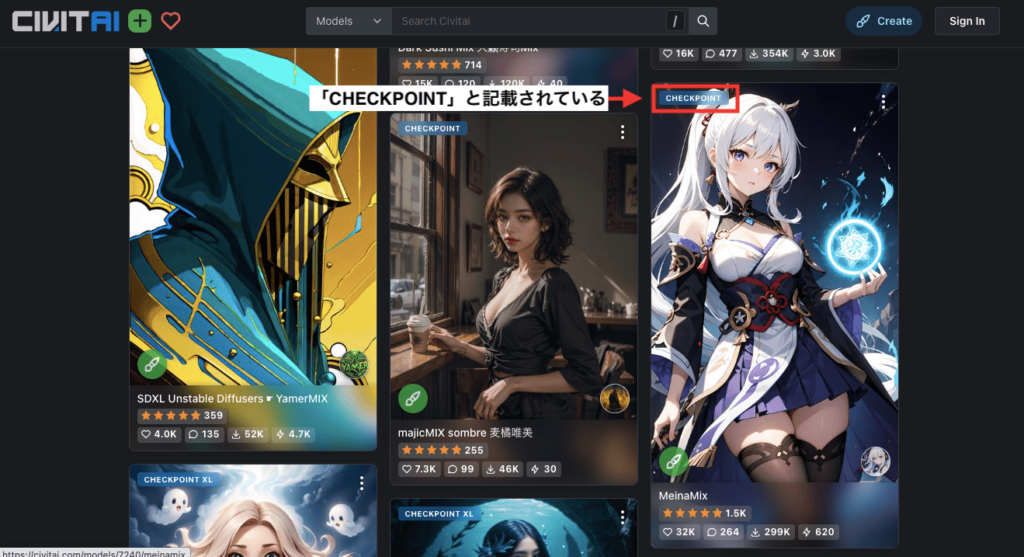
Checkpointモデルかどうかを判断する方法として
CivitAIの場合は、各モデルの左上の場所に「CHECKPOINT」と記載されています。
Checkpointには、リアル風の画像生成に向いているモデルと、アニメ風の画像生成に向いているモデルがあります。
モデルのサムネ画像から、リアル風なのかアニメ風の画像生成に向いているのかが確認できます。
生成したい絵柄に合わせてモデルを選択するようにしましょう。
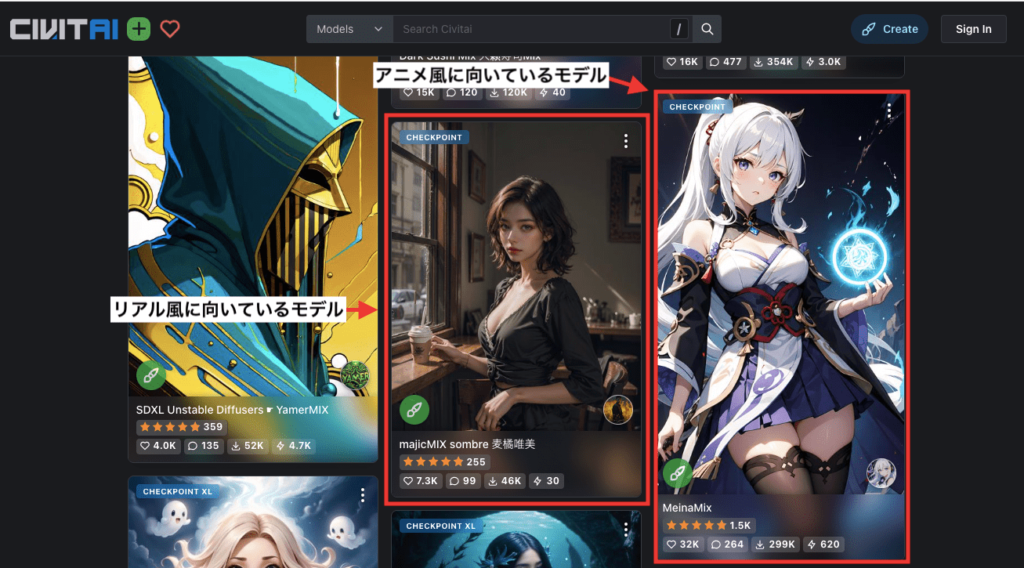
以下の画像は、アニメ風に向いているモデルと、リアル風に向いているモデルで画像生成した結果になります。
アニメ風のモデルで実写のようなリアル風に生成しようとしても難しく
その逆のリアル風のモデルでアニメ風にさせようとするのも難しいので
それぞれに対応したCheckpointモデルに変更するようにしましょう。

Google Colabを使っている方でモデルの入れ方が分からない場合は
詳しく以下の記事で解説してるので読んでみてください。

リアル風とアニメ風のおすすめCheckpointモデルについては以下の記事で解説しています。

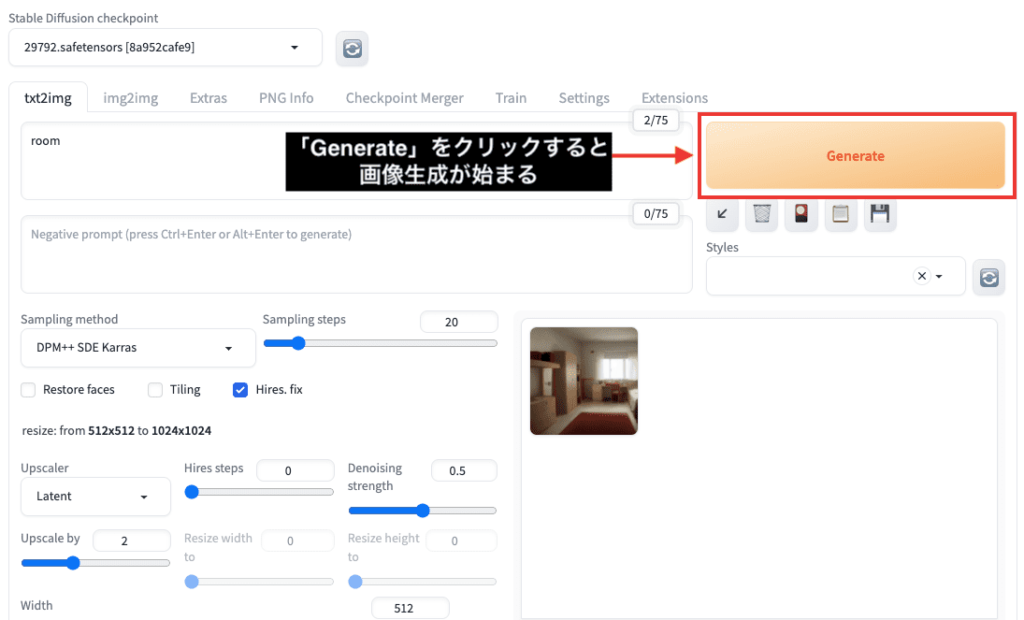
画像の生成方法

画像を生成する場合は、右上にある「Generate」と書かれた黄色のボタンをクリックすることで開始されます。
設定方法によって生成されるまでの時間が変わります。
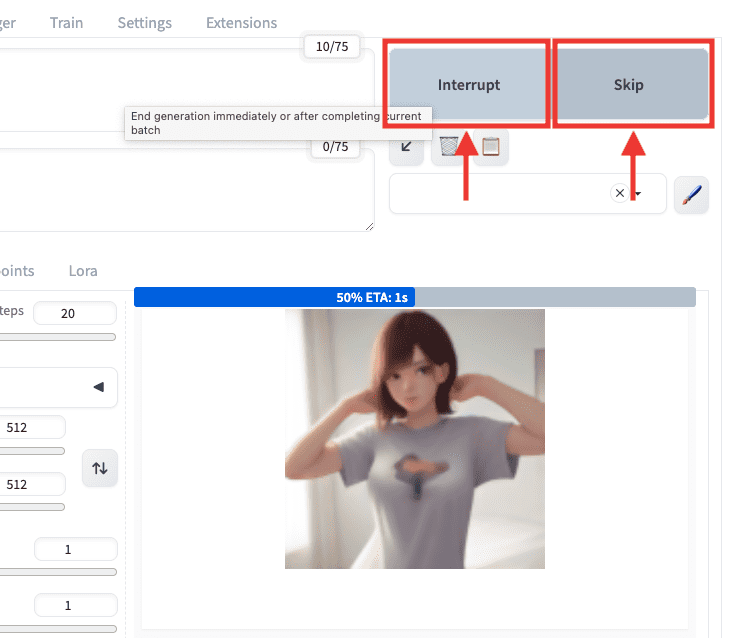
画像生成の途中で停止する方法
以下の画像のように、画像生成中に停止したい場合は、「Interrupt」か「Skip」をクリックすることで可能です。
| Interrupt | 1度クリックすると「Interrupting…」に変わります。 再度クリックすると、すぐに全ての生成を停止します。 |
| Skip | 「Batch count」項目の数値が「2」以上の場合は 現在の生成を中断して次の画像を生成します。 |
生成途中に画像がぼやけて表示されるのですが
理想的な画像生成になっていない場合などに使用すると
時間短縮できるので上手く活用しましょう。
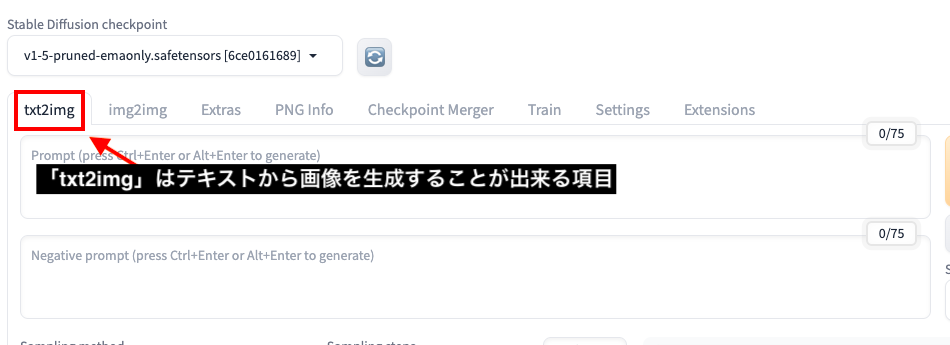
txt2imgはテキストから画像生成できる

「txt2img」では、テキストから画像生成するための項目になっています。
ここでは「txt2img」内にある各項目について詳しく解説します。
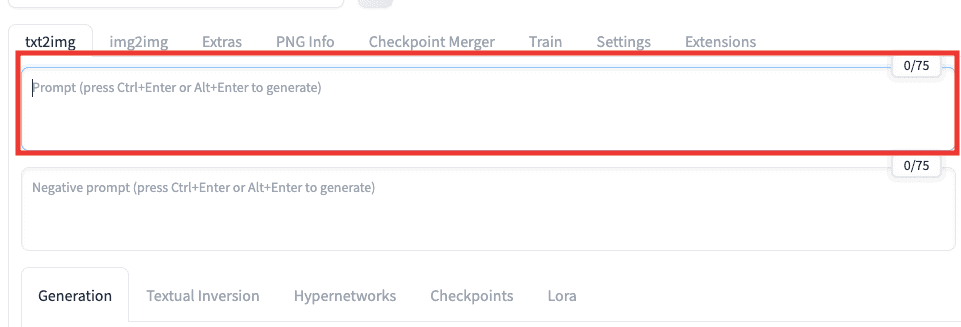
プロンプト(呪文)について
以下の画像にある通り、上部にあるテキストを入力する場所(私の場合はプロンプト入力場所と呼んでいます)では
生成したい内容をテキストで指示します。
指示することを「プロンプト」と言います。
プロンプトは別名で呪文とも呼ばれますが
執筆現在はプロンプトと呼ばれるのが主流になっています。
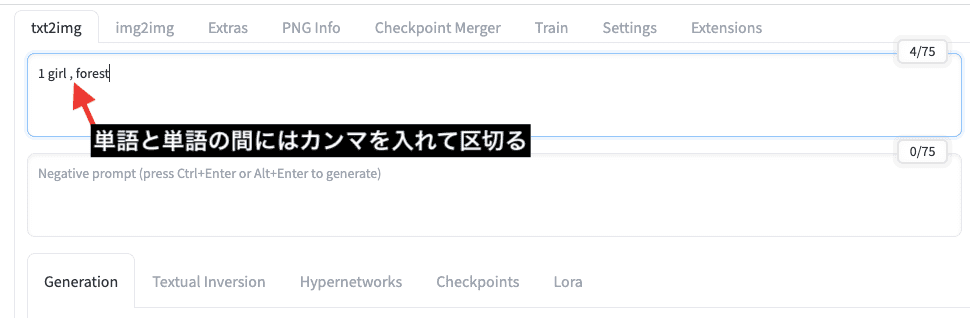
例えば、1人の少女が森の中にいる画像を生成したい時は
「1 girl , forest」のプロンプトを入力します。
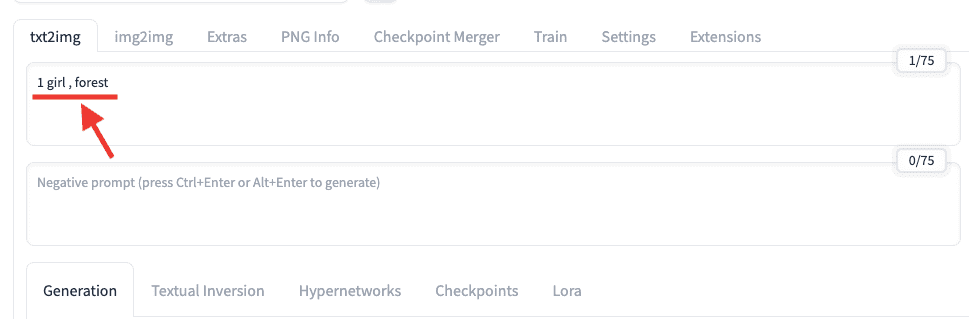
単語と単語の間には、「,(カンマ)」を入れて区切るようにしましょう。
以下は画像生成した結果になります。
入力したプロンプト通り、1人の少女が森の中にいる画像を生成できました。
このようにプロンプト入力場所では、生成したい内容を入力しましょう。

「1 girl , forest」だけのプロンプトを入れて画像生成すると
先ほどのクオリティの高い画像ではなく、以下の画像のようにクオリティが低い結果になります。

クオリティを高くするプロンプトを知りたい方は
以下の記事で解説しているので、合わせて読んでみてください。


ネガティブプロンプトについて
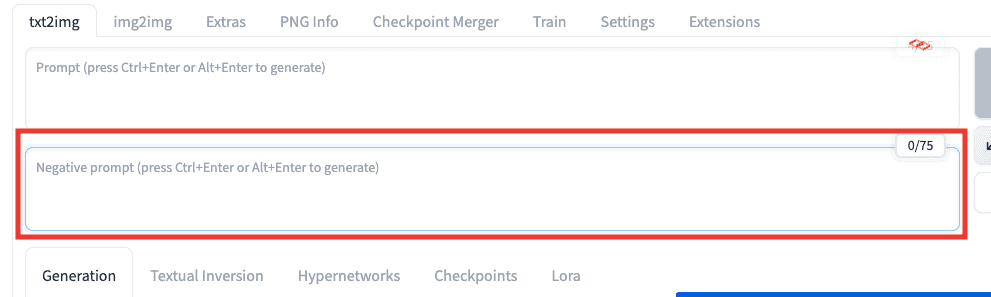
プロンプト入力場所では、生成したい内容を入れる場所でしたが
以下の画像にある通り、下部にあるテキストを入力する場所(私の場合はネガティブプロンプト入力場所と呼んでいます)では
省きたい内容をテキストで指示します。
省きたい内容を指示することを「ネガティブプロンプト」と言います。
生成する指示 → プロンプト
生成しない指示 → ネガティブプロンプト
と言われています。
ネガティブプロンプトの使い方の例として、
まずはプロンプト入力場所に「1 girl , river」と入力して、1人の少女が川にいる画像を生成してみます。
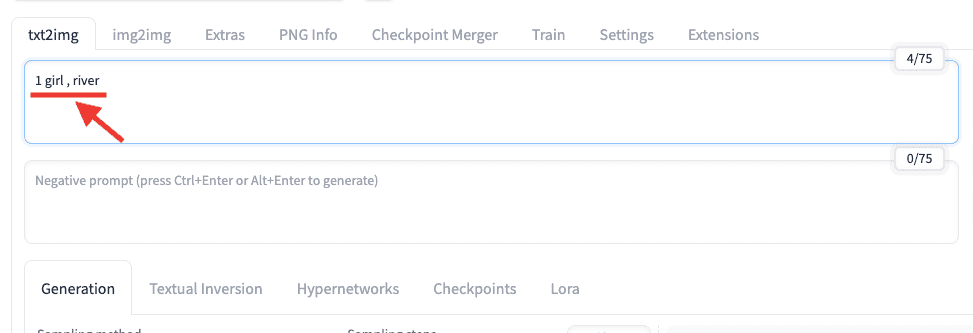
以下の画像のように生成されましたが、「帽子を省いた画像を生成したい」と思ったとしましょう。

帽子を画像生成したくないので、ネガティブプロンプト入力場所に「hat」と入力します。
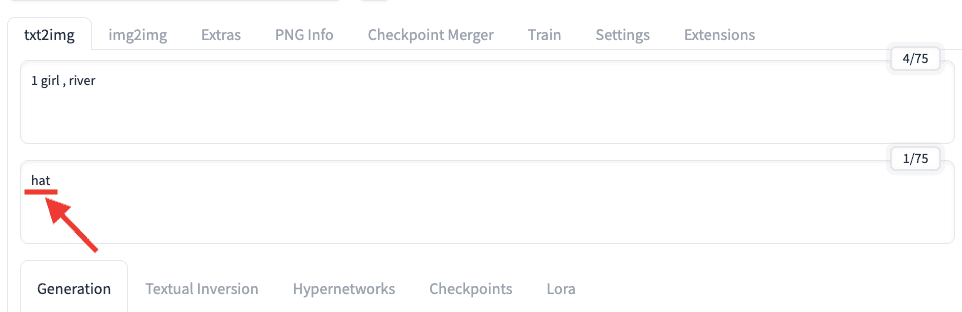
以下は画像生成した結果になります。
帽子を被っていない画像生成ができました。
このようにネガティブプロンプトでは
画像生成しない指示をすると省くことができるため
よりイメージしている結果に近づけていくことが可能になります。

ネガティブプロンプト入力場所に省きたい内容を入れても、必ずしも省けるとは限りません。
モデルによっては、省ける確率が低かったり、全く省けない場合があります。
そういった時は、次のことを変更することで解決できる場合があります。
・Sampling methodを変更する
・Schedule typeを変更する
または、別の対処法として「強調構文」を使用すると省ける場合があります。
以下の記事で「強調構文」について解説しているので、上手く省けない場合は読んでみてください。

クオリティを高くすることができる、必須で入れた方が良いおすすめのネガティブプロンプトについては
以下の記事で解説しているので合わせて読んでみてください。

Sampling methodについて

「Sampling method」は、ノイズ除去する方法を変更できます。
変更することで、それぞれ違った生成結果になります。
以下の画像では、「Sampling method」を「DPM++ 2M」「Euler a」「DDIM」で生成した結果になります。
「DPM++ 2M」と「DDIM」は少し似てはいるものの、全て違った生成結果になっています。

Sampling methodによって生成される特徴が変わります。
変更すると、次のことが解決できる場合があります。
・反映されなかった呪文が反映されるようになる
・生成できなかったポーズが生成されるようになる
・胴体・腕・脚などの部位が分離する確率が低くなったり、崩れにくくなる
初回設定では「Euler a」になっていますが、試しに1枚ずつ試していくことを推奨します。
1つずつ使っていく内に「これが良い」というものが出てきます。
モデルによっては最適な「Sampling method」が違うので、1つずつ検証して試行錯誤する必要があります。
比較的どのモデルでも綺麗に仕上がりやすいおすすめ設定は以下の2つになります。
・Euler a
・DPM++ 2M Karras
上記2つのサンプラーは、他のSampling methodよりも良い生成結果がされやすい傾向にあるので試してみてください。
Sampling methodの詳細については、以下の記事で解説しているので読んで見てください。

Schedule typeについて
「Schedule type」は、Stable Diffusion Web UIがV1.9になってから新しく追加されました。
「Sampling mtehod」と同じように変更することで違った生成結果になります。
以下の画像では、「Uniform」「Karras」「Exponential」で生成した結果になります。
どれも似てはいるのですが、腕や服装の絵柄が少し変化していたりと全体が少し違っています。
変更すると理想的な画像を生成できる場合があるので、上手く生成できなかった場合は試してみてください。

Sampling stepsについて

「Sampling steps」は、ノイズを除去する回数になります。
数値が小さいほど、生成速度は早いですが、クオリティが低いです。
数値が大きいほど、生成速度は遅いですが、クオリティが高くなります。
一定数値に到達すると、そこまでクオリティが変わらなくなってくるので、「20〜40」くらいの範囲でいいかなと思います。
数値を大きくするほど生成時間が長くなります。
以下の画像では、「Sampling steps」を「10」「20」「40」で比較した結果になります。
「10」の方では、目の付近に黒い物体が生成されていてクオリティが低いです。
「20」以上では、クオリティに差はあまり感じられないものの、「40」の方が「20」よりも顔と身体のバランス比率が取れていてクオリティが高く見えます。
このように、Sampling stepsの値を大きくするほど綺麗な仕上がりになりやすいです。

アニメ風のイラストでは、「20」の設定でも良い品質になりますが
リアル風(実写)の場合では、「40」以上で合わせた方が良い結果になる傾向にあったので
参考程度に設定してみてください。
Hires.fix(高品質・高解像に出来る)

「Hires.fix」を使用すると
高品質・高解像になってクオリティを高くできるので
必須で使用することを推奨します。
「Hires.fix」の左側にあるチェックマークを入れることで適用できます。
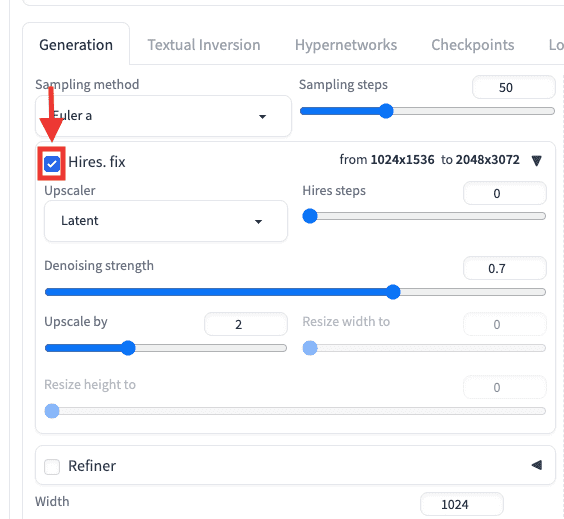
以下の画像は、「Hires.fix」無しと有りの比較結果になります。
右側の「Hires.fix」有りの方が、クオリティが高くなっています。
生成時間は長くなりますが、質を重視するなら必ず使用した方がいい機能です。

「Upscaler」の項目では、高解像にさせる方法を変更します。
変更すると、シャープさが強くなったりする場合があります。
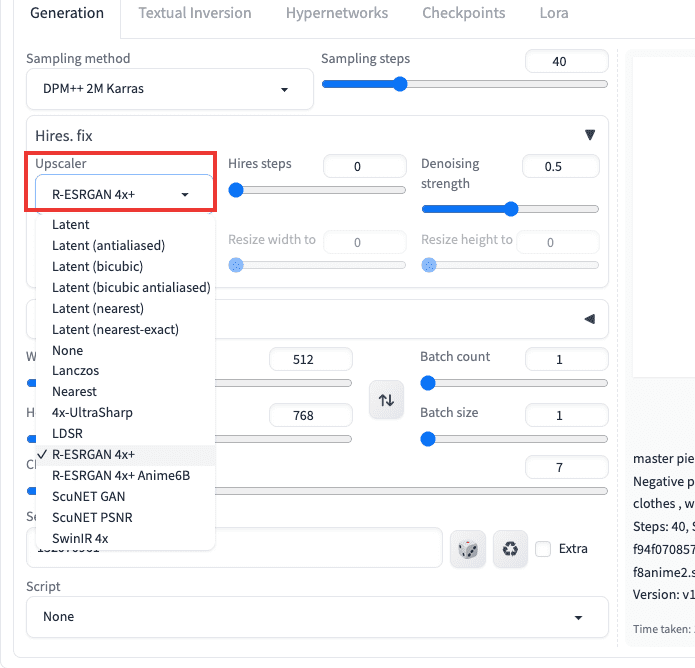
以下の動画では、「Latent」「SwinIR 4x」を比較した結果になります。
「Latent」では、柔らかい印象で高解像に画像生成されています。
「SwinIR 4x」では、シャープな印象で高解像に生成されいます。
このように処理方法によって微妙に塗り方などが変わったりするので
「Upscaler」をいろいろ変えてみて良いと思った方を選択しましょう。
高画質化・解像度を上げてクオリティを高くする「Hires.fix」の詳しい使い方については以下の記事で解説しています。

RefinerでCheckpointモデルを合成する
「Refiner」は、Stable Diffusion Web UIがV1.6になってから新しく追加された機能になります。
使用することで、Checkpointモデル同士を組み合わせた画像生成をすることが出来ます。
Checkpointモデルが2つ以上入っていないと組み合わせることができません。
使用方法は「Refiner」の右側にある逆三角形の部分をクリックして開きます。
「Checkpoint」項目内で組み合わせたいモデルを選択してください。
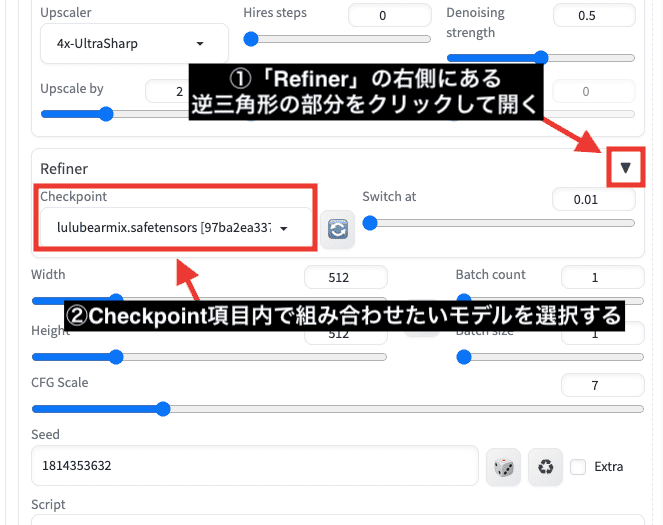
以下の動画では、「Refiner」無しと有りを比較しました。
「Refiner」有りでは、Checkpointモデル同士を組み合わせて画像生成できています。
上手く組み合わせることで、より質を高くすることが出来るので活用してみてください。
Refinerの詳しい使い方については以下の記事で解説しています。

Width・Height(画像サイズの変更)

「Width」は、生成する画像サイズの横の設定になります。
「Height」は、生成する画像サイズの縦の設定になります。
右側にある「上下矢印アイコン」は、横と縦のサイズが逆に設定されます。
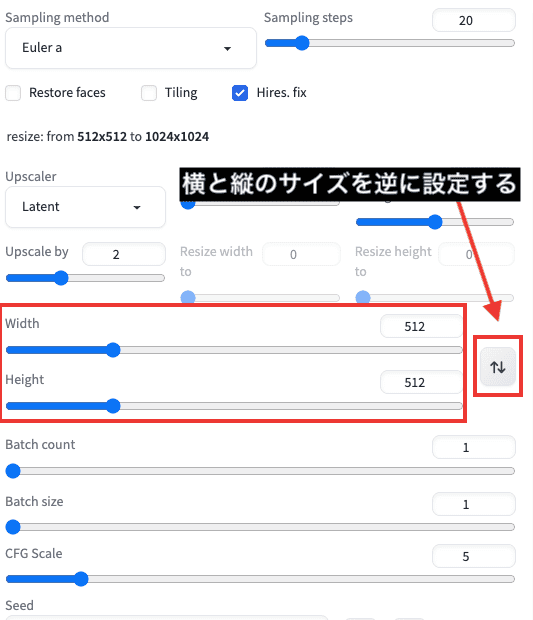
画像サイズは意外と重要です。
最適な画像サイズ(アスペクト比率)に変更すると、次のことが解決できる場合があるので試してみてください。
・生成できなかったポーズが生成されるようになる
・胴体・腕・脚などが崩れにくくなったりする
・生成できなかった構図(全身など)が生成されやすくなる
モデルや理想とする画像によって最適な画像サイズは変わるので試行錯誤してください。
体が崩れにくい画像生成が出来る、おすすめの画像サイズについて以下の記事で解説しています。

Batch count(1度に複数枚の生成)

「Batch count」は、1度に画像を連続で生成する枚数の設定になります。
例えば、10枚を1度に連続生成したい場合は「10」の数値で設定します。
生成枚数を大きくするほど生成時間が比例して長くなります。
Batch sizeについて

「Batch size」は、一度に画像を大量に生成したい場合に使用します。
「Batch count」の設定では、最大100枚までしか生成できません。
1度に200枚連続生成したい場合は
「Batch count」の数値を「100」にしてから
「Batch size」の数値を「2」に設定することで
100(Batch count) × 2(Batch size) = 200枚の生成が可能になります。
「Batch size」を上げ過ぎると途中で止まる(VRAM不足)場合があるので
最大でも「2」くらいにすることを推奨します。
以下の記事では、「Batch Count」と「Batch Size」について詳しく解説しています。

CFG Scale(プロンプトに従う強さの調整)

「CFG Scale」は、プロンプトに従う影響度を調整することができます。
・プロンプト内容に従いにくくなり、AIの影響が強くなる
・数値が「1〜3」くらいで小さすぎると品質が劣化する
・全体的に色が薄い・シャープさのない柔らかい印象になる
・プロンプト内容に従いやすくなる
・数値が「15」以上くらいになると、逆にプロンプトに従いにくくなったり品質が劣化する
・全体的にシャープな印象になる
おすすめの設定としては「5〜12」くらいの範囲で合わせると品質の良い仕上がりになります。
このあたりも試して適切なバランス数値を見つけて合わせましょう。
「CFG Scale」の数値設定は、理想的な画像生成をさせる確率を上げるために必要な項目です。
CFG Scaleの詳細については以下の記事で解説しています。

Seedについて

Seedは「-1」にすると、画像生成する度にランダムな数値にします。
ランダムな数値にすることで、生成する度に違う画像を生成できます。
画像生成したSeed値の確認は
選択した画像の下にプロンプトなどのパラメータ情報が載ってる場所に記載されています。
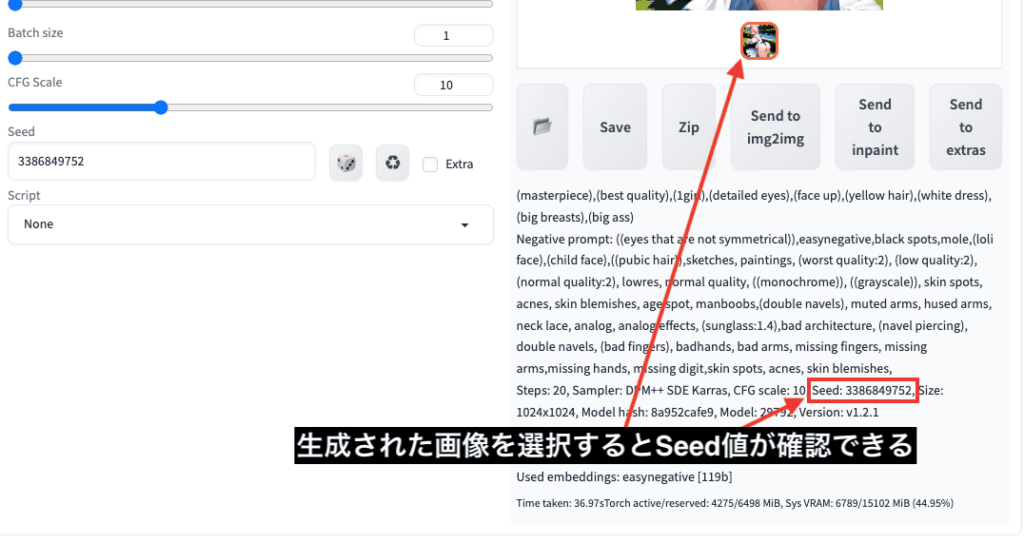
Seedは数値を固定することで
全く同じ画像生成をしたり、似たような特徴で画像生成できます。
例として、特定のSeed値に固定して、白色のブラウスから茶色のブラウスに変更して似たような画像を生成してみます。
プロンプト内には「blouse」の呪文を入れてから画像生成します。
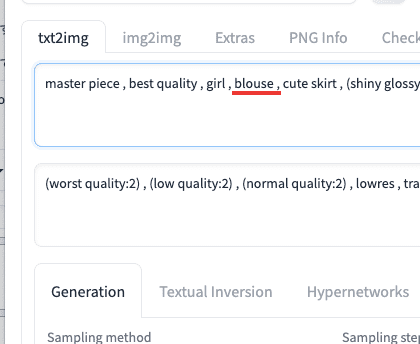
以下の画像は生成した結果になります。
白色のブラウスで画像生成されています。

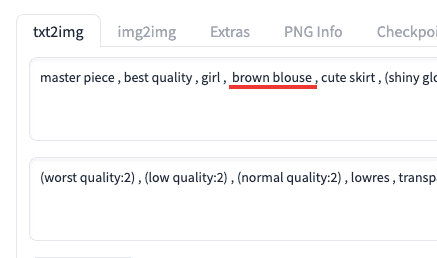
次はプロンプト内に「brown blouse」と修正し、茶色に変更して似たような画像を生成します。
先ほど生成した白色ブラウス画像のSeed値を、左側にあるSeed項目にコピペしてから画像生成します。
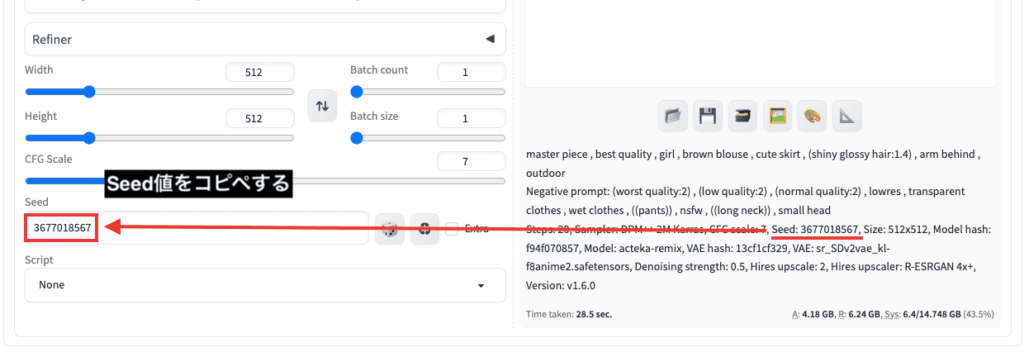
以下の画像は比較した結果になります。
茶色のブラウスに変更されて、似たような特徴で画像生成できています。
このようにSeed値を固定すると、服装・髪色・目の色・背景などを変更して似た特徴で画像生成できます。

ですが、必ずしも特徴を引き継いで画像生成できるとは限りません。
プロンプトを2つ以上追加して生成すると、特徴が引き継がれていない全く別の画像生成がされる場合があったり、Seedによっては引き継がれない場合があります。
Seedの使い方についてさらに詳しく知りたい方は
以下の記事で解説していますので是非読んで見てください。

Scriptについて
「Script」項目では、主に連続した画像生成をする度に呪文を自動で切り替えたい場合や
「Generate」ボタンをクリックしたときに、「Sampling steps」などの各項目の数値などを
「20」「40」「60」にして連続で自動生成させたい場合などに使用します。
ここでは、「Script」内にある「Prompt matrix」「Prompts from file or text box」「X/Y/Z plot」の3つの使い方についてそれぞれ解説していきます。
Prompt matrix
「Prompt matrix」は、比較画像を生成したい場合に使用するといいでしょう。
使い方の例ですが、プロンプト内に「flower | tv | door」とカンマで区切るのではなく、単語と単語の間に「 | 」を入れます。

画像生成すると以下の生成がされます。
1回目の左上は「flower」のみ
2回目の右上は「flower , tv」
3回目の左下は「flower , door」
4回目の右下は「flower , tv , door」
これらは4通りの方法で画像生成されており、比較結果などで使用するといいと思います。

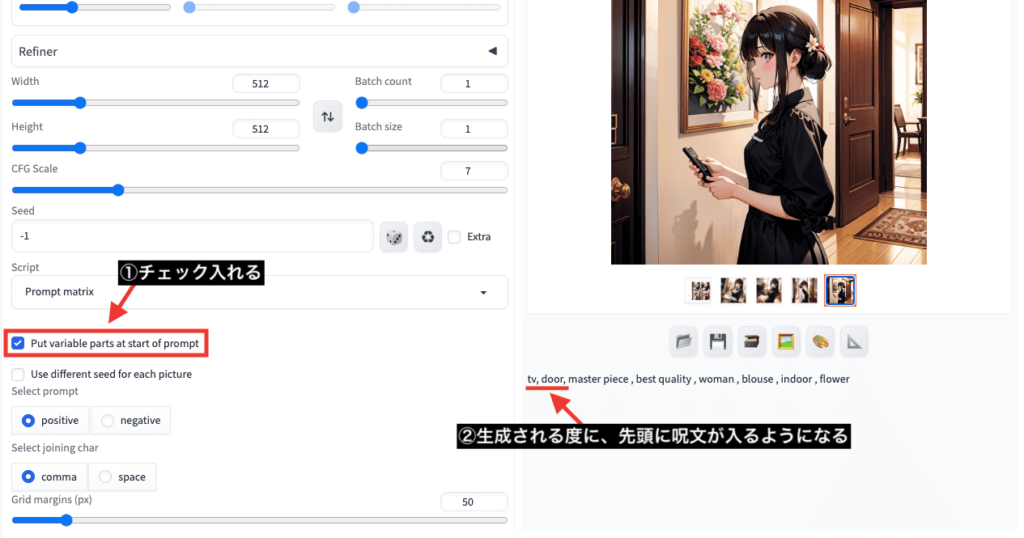
「Put variable parts at start of prompt」にチェックを入れると
画像生成される度にプロンプト入力場所の先頭に1つずつ呪文が入るようになります。
チェックがない場合は、後ろ側に呪文が追加されていきます。
後ろに呪文があると反映されにくい場合があるのですが
先頭に呪文が入ることによって生成されやすくなります。
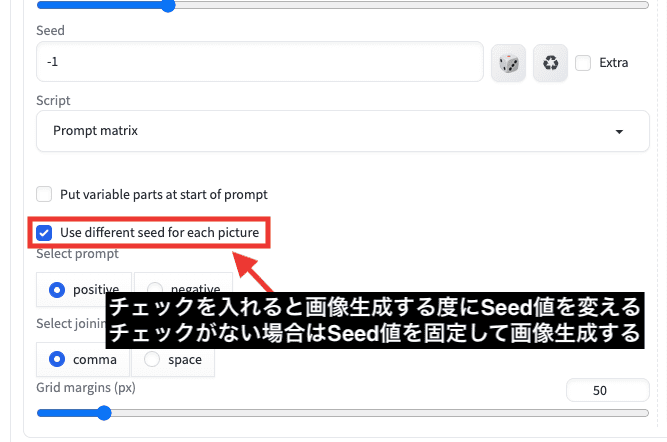
「Use different seed for each picture」にチェックを入れると
画像生成する度にSeed値が変わります。
チェックがない場合は、Seed値を固定して画像生成します。
「positive」を選択すると、ポジティブプロンプトに対して適用させます。
「negative」を選択すると、ネガティブプロンプトに対して適用させます。
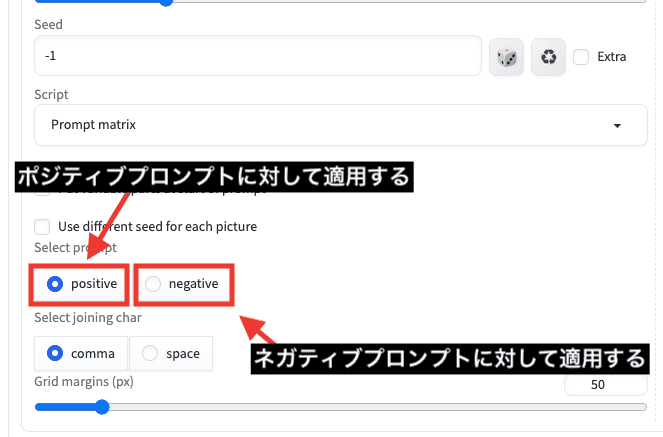
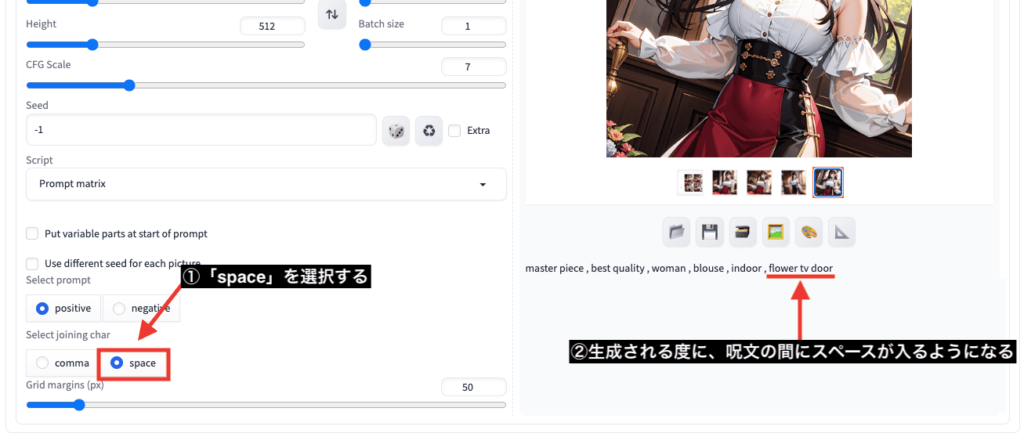
「Select joining char」項目では
「comma」を選択すると、呪文が追加される度に「,(カンマ)」を入れて区切ります。
「space」を選択すると、スペースが入るようになります。
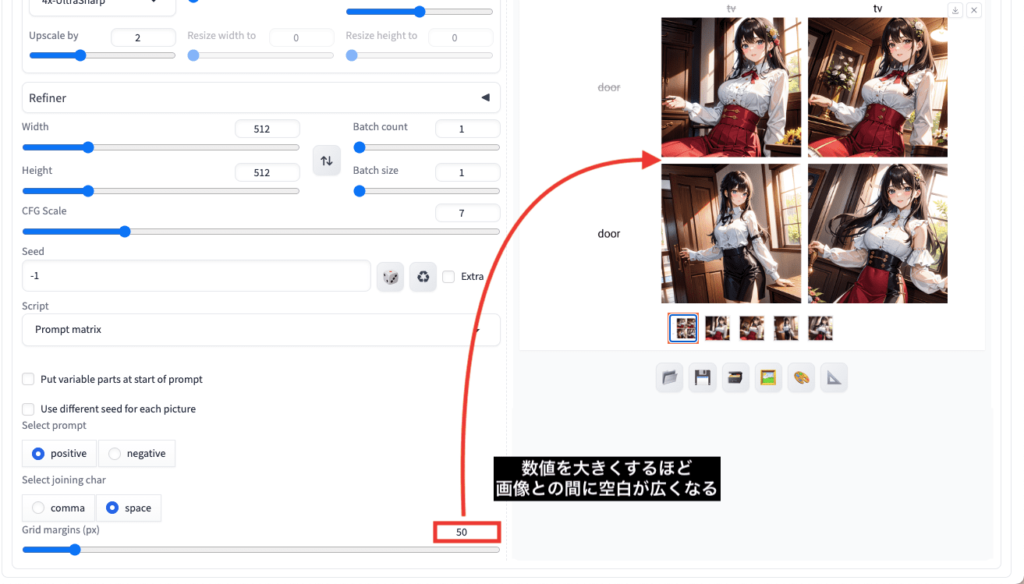
「Grid margins(px)」では数値を大きくするほど
画像との間に空白を広くさせることが出来ます。
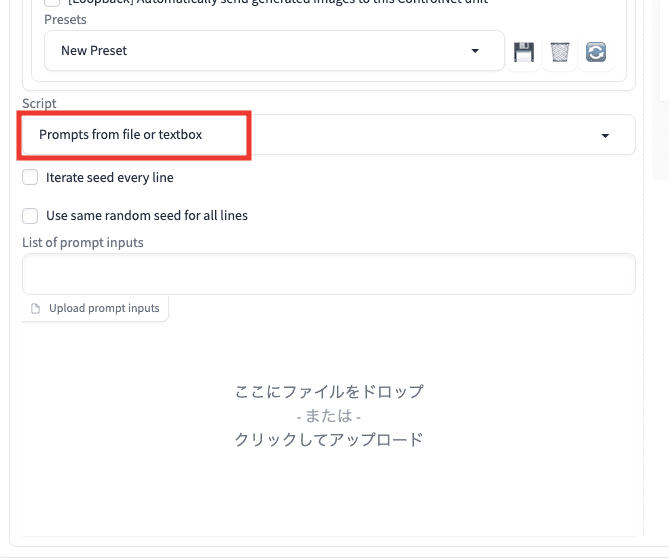
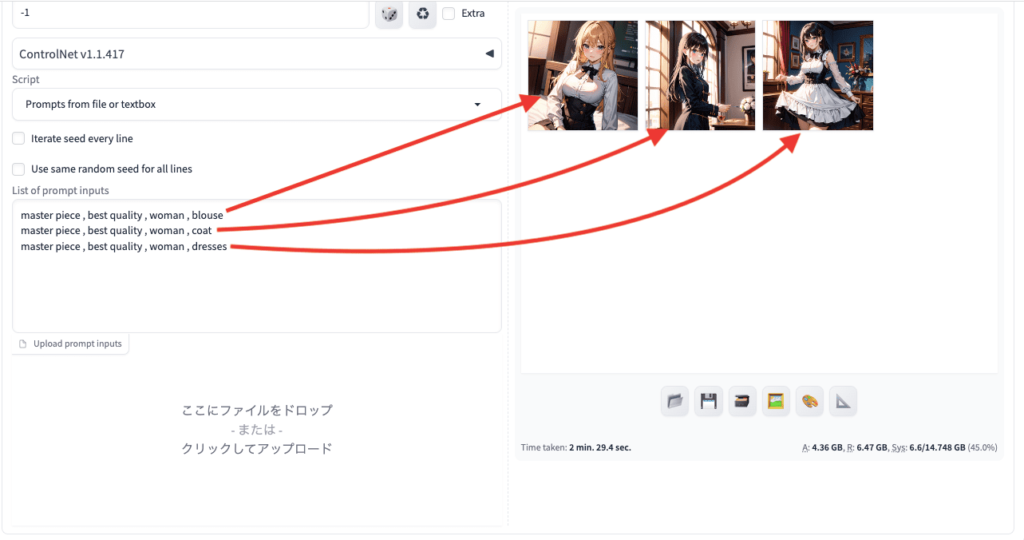
Prompts from file or textbox
1度の連続生成で別の呪文に自動で切り替えて生成させたい場合は
「Prompts from file or text box」を使用しましょう。
使い方の例ですが、1度にブラウス・コート・ドレスの順で連続生成させたい場合は
以下の画像のように、「List of prompt inputs」内の項目で、1行ごとに各呪文を入れてから画像生成します。
「Prompts from file or textbox」を使用すると、プロンプト内で入力した呪文は全て無効になり
「List of prompt inputs」内で記載したプロンプトだけが反映されます。
1度の画像生成で連続で呪文を切り替えて生成してくれるので上手く活用しましょう。
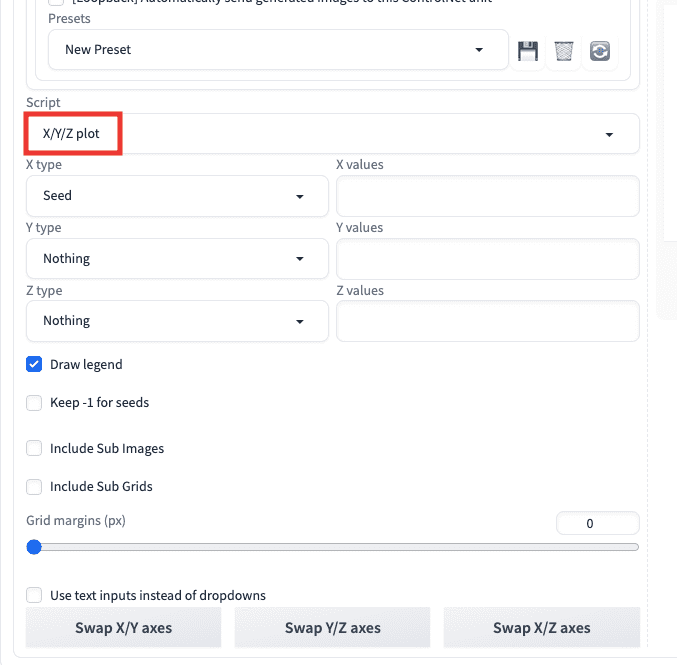
X/Y/Z plot
「X/Y/Z plot」では、1度の画像生成で髪型や服装などを連続で変えて画像生成したい時などに使用します。
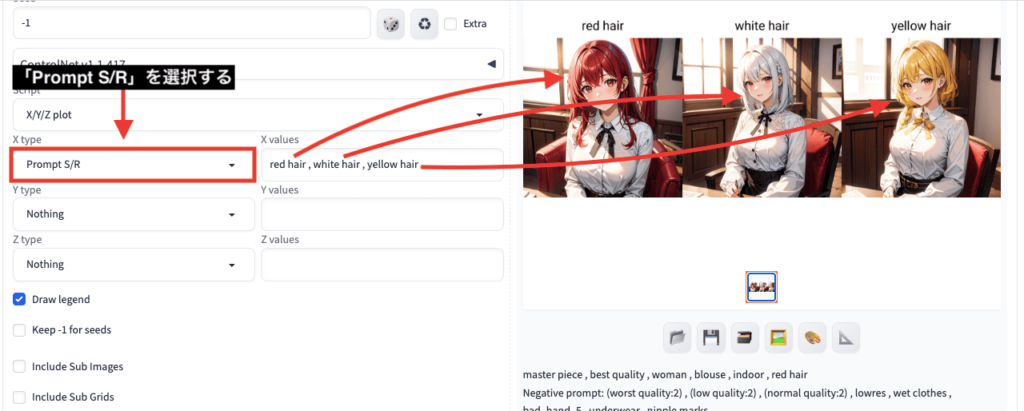
使用例として、髪色を「赤→白→黄」にして連続生成したい時に
プロンプト入力場所には「red hair」とだけ記載します。

以下の画像のように、「X/Y/Z plot」にある「X type」項目から「Prompt S/R」を選択します。
「X values」項目内に「red hair , white hair , yellow hair」と呪文を入力してから画像生成することで
「赤→白→黄」の髪色にして連続で画像生成することが出来ます。
通常であれば、プロンプト入力場所に「red hair」を入力して画像生成した後に
再度プロンプト入力場所で「white hair」に変更してから画像生成するので手間がかかってしまいます。
そこで、「X/Y/Z plot」を使用することで、1度の画像生成で連続で呪文を変えることが出来るので手間を省けます。
非常に便利な機能なのでおすすめです。
他の用途として、どのように変化するのかを比較して確認したい場合などにも使用します。
「X/Y/Z plot」の詳しい使い方については、以下の記事で解説しているので読んでみてください。

img2imgは画像から似た画像を生成する

「img2img」の項目では、画像から似たような特徴の画像を生成する場合に使用します。
参照画像を「img2img」内にアップロードしてから
プロンプトやネガティブプロンプトを記入して画像生成します。
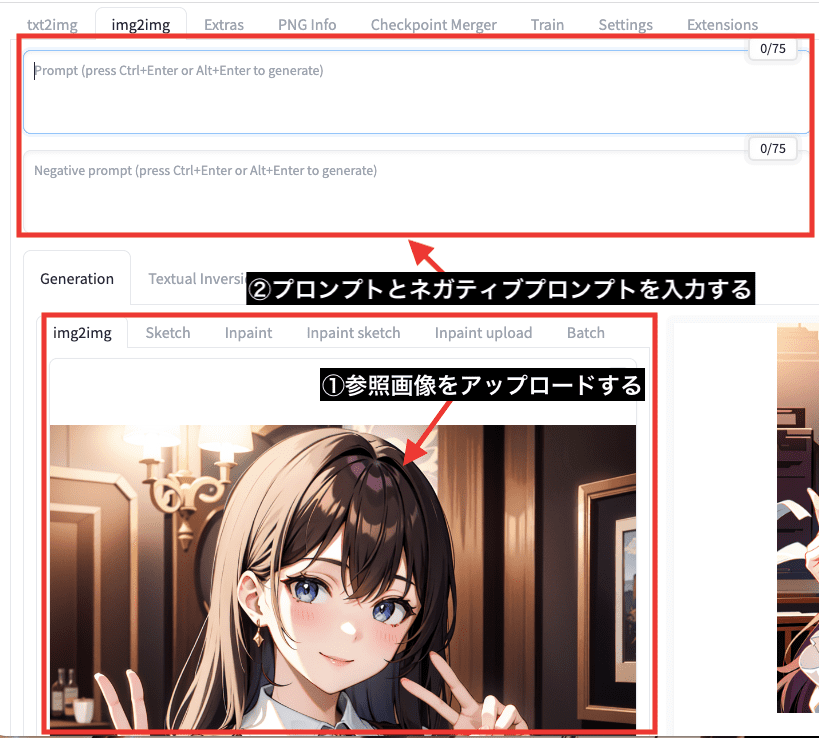
以下の画像は、「元画像」と「img2img」で生成して比較した結果になります。
右側にある「img2img」を使用した画像では、元画像と似たような特徴で生成できていることが確認できます。
このように「img2img」を使用することで
参照画像と同じような画像生成をすることが出来るので上手く活用しましょう。

img2imgの詳しい使い方については以下の記事で解説しています。

Extrasは高品質・高解像度にさせる

「Extras」項目では
画像生成した作品を高画質・高解像度にすることが出来るので
最終段階の仕上げとして使用するといいでしょう。
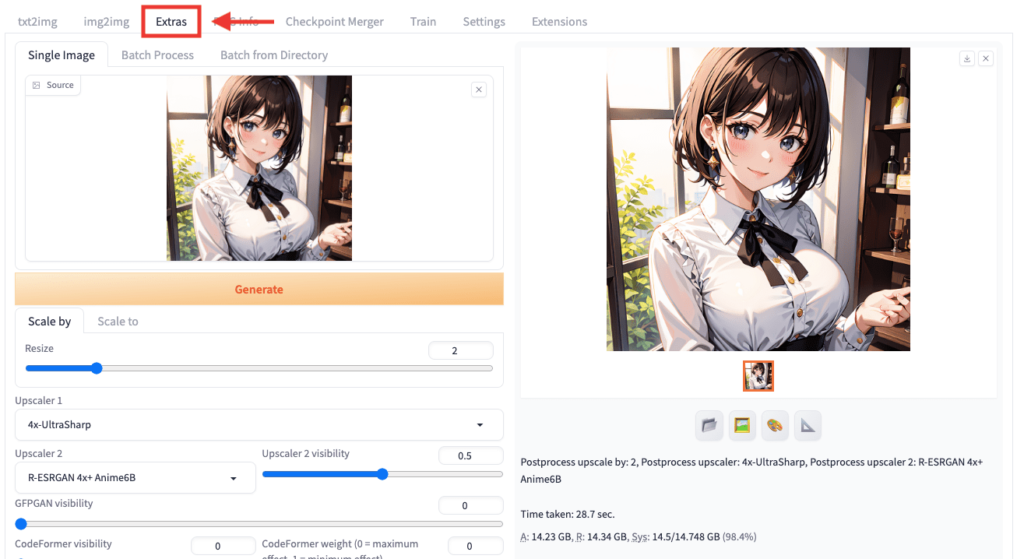
「Resize」項目では、最大8倍まで画像のスケールを大きくできますが、生成まで時間がかかります。
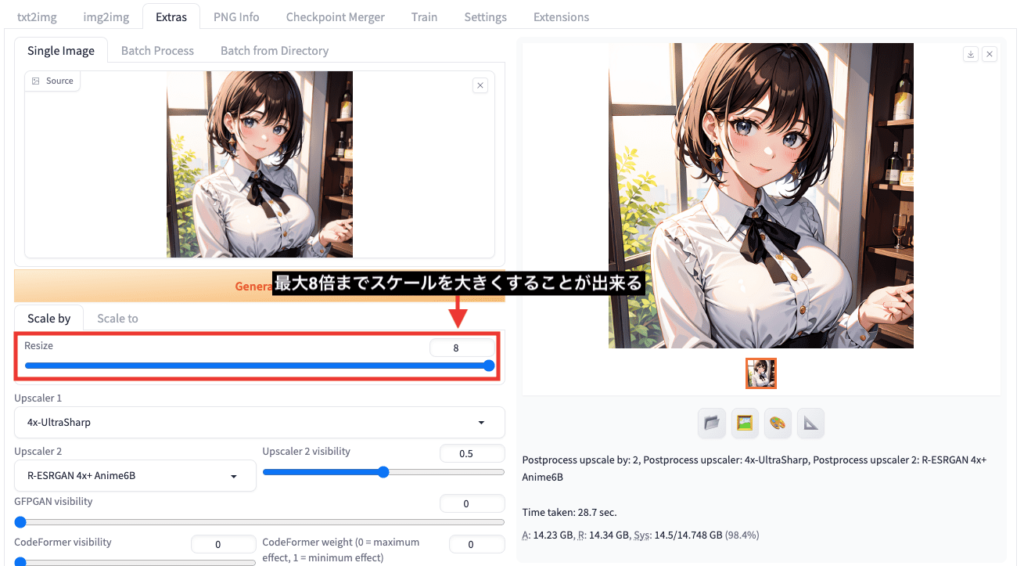
以下の画像は、「元画像」と「Extras」で生成して比較した結果になります。
「Extras」を使用することで、
ぼやけがなくなり高品質になってクオリティが高くなるので利用してみてください。

Extrasの詳しい使い方について、以下の記事で解説しています。

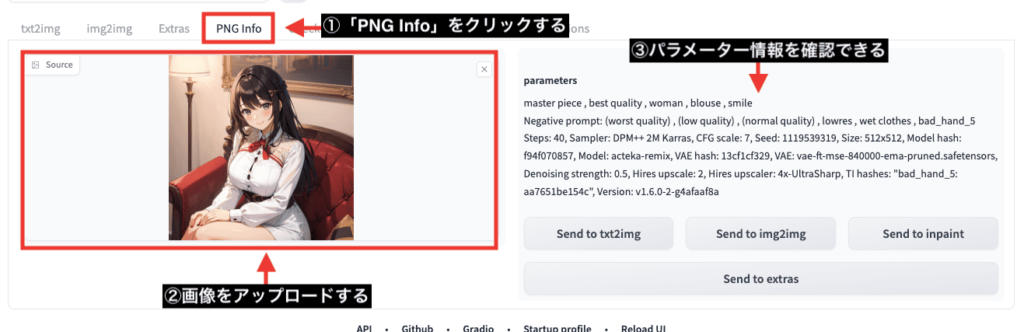
PNG Infoでパラメーターを再利用する

「PNG Info」項目では、画像生成したプロンプトやネガティブプロンプトなどの
パラメータ情報を確認できます。
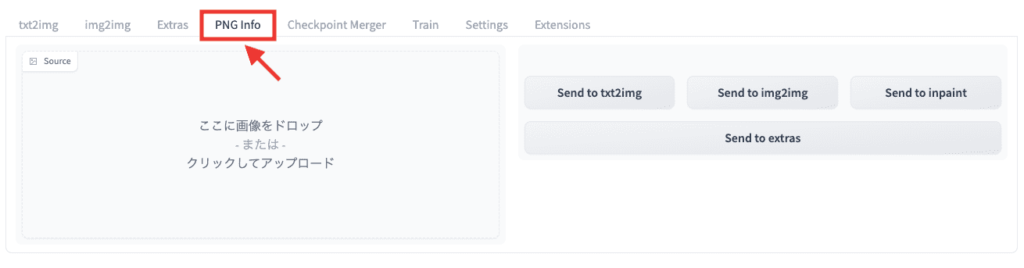
確認するには、左から画像をアップロードするだけで、右側に全てのパラメータ情報が表示されます。
ですが、一度生成した作品を再度pngにしたり、jpegなどに加工した場合はアップロードしてもパラメータ情報が確認できなくなります。
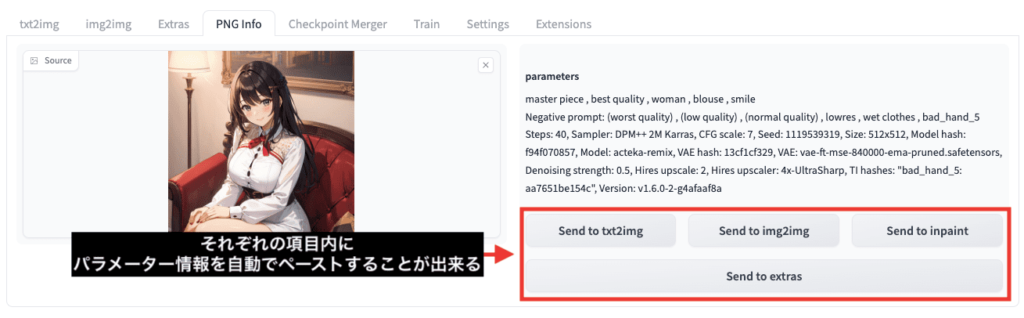
以下の画像にある「Send to 〇〇」項目内のボタンをクリックすると
パラメータ情報を自動でペーストします。
プロンプトやネガティブプロンプトなどを再利用する時に
非常に便利な機能なので活用してみてください。
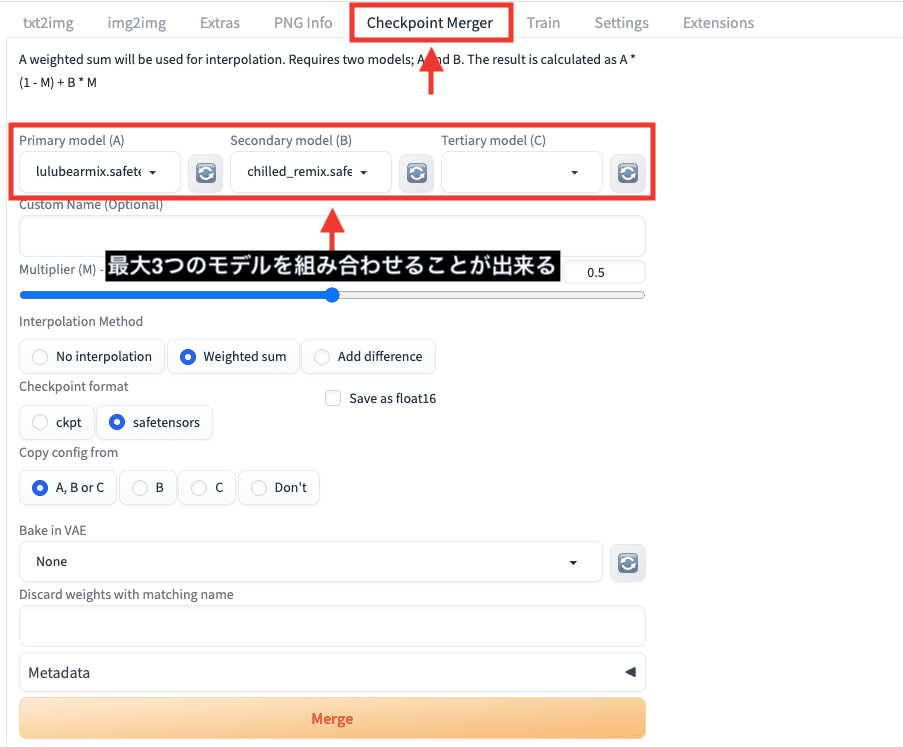
Checkpoint Mergerはモデルを合成できる

「Checkpoint Merger」項目では
Checkpointモデル同士を最大3つまでマージ(合成)させて
新しいCheckpointモデルを作成できます。
画風を組み合わせたい場合に使用します。
以下の画像は、アニメ風とリアル風の2つのモデルを組み合わせて生成した結果になります。
一番右側は、2つのモデルを生成した結果になるのですが
上手く合成して画像生成できています。
このように、画風を組み合わせて画像生成したい場合に使用してみてください。

Checkpoint Mergerの使い方については以下の記事で解説しています。

LoRAでクオリティを高くする

LoRAを使用すると、次のことができます。
・アニメキャラを生成できる
・画風を変える
・描き込み量を増やす
・特定のポーズにさせる
上記は一部であり他にも多くのことができます。
LoRAは、追加学習させるモデルであり、補助的な役割をしています。
例えば、ピクセルアートの画風にしたい時に
使用しているCheckpointモデルだけで「pixel art」の呪文を入力しても生成できない場合があります。
そこで、ピクセルアートの画風に特化したLoRAを使用することで
ピクセルアート風の画像を生成できるようになります。
CheckpointモデルとLoRAを上手く組み合わせることで
よりクオリティを高くさせることが可能になります。
Checkpointモデルと同様に、「CivitAI」や「Hugging Face」のサイトからLoRAをダウンロードすることが出来ます。
LoRAはプロンプト入力場所に追加すると適用できます。

左上にある「Stable Diffusion checkpoint」の項目からLoRAは使用できません。
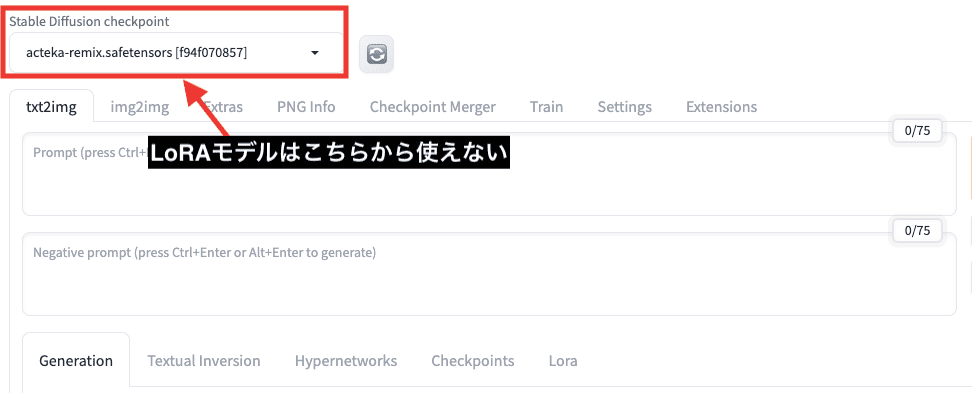
Checkpointモデルとは使用方法が異なっており
LoRAはプロンプト入力場所に追加すると使用できます。
プロンプト入力場所にLoRAを追加したときに
右側にある数値を調整すると、LoRAの影響度を設定できます。

以下の画像は、より詳細に描いて生成してくれる
「Add More Details – Detail Enhancer / Tweaker (细节调整) LoRA」のLoRAを使用して
LoRA数値を「0.5」「1」で生成した結果になります。
右側にある「LoRA 1」では、左側の「無し」と比べると、より詳細になって画像生成できています。
真ん中の画像では半分のLoRAの影響力で生成しており、少しだけ詳細にして画像生成できています。
このようにLoRAを使用すると、クオリティを高くしてくれるので、ぜひ導入してみてください。

LoRAモデルの詳しい使い方については以下の記事を読んでみてください。

必須で入れた方がいいおすすめLoRAモデルについては以下の記事で解説しています。

VAEは全体を明るくする

「VAE」を使用しない場合、以下の画像のように色が薄い感じに仕上がったり
全体がぼやけているような感じになったりする場合があります。

「VAE」を導入して使用すると、以下の右側の画像のように
全体的に色を明るくできるので必須で導入した方がいいです。

「VAE」は数多く配布されており
VAEによって処理方法が変わるので、色の明るさに違いが出ます。
VAEは全体を明るくできるだけでなく
一部分を綺麗に修正したりする場合もあるので
必須で使用することを推奨します。
VAEの導入方法と使い方などについて、詳しくは以下の記事で解説しています。

クオリティを高くするおすすめのVAEについては↓

ControlNetは塗り方を変えたりポーズを指定できる

「ControlNet」を導入することで、次のことができるようになります。
・アップロードした画像から線画のみを参考にして画像生成する
・アップロードした画像からポーズのみを参考にして画像生成する
・崩れた手を綺麗に修正する
上記は一部であり、他にも多くの機能があります。
使いこなせると便利なので、導入してControlNetをマスターしておきましょう。
Google Colabを使っている人で、コードが分からなくても簡単にControlNetを導入する方法について
以下の記事で解説しているので読んでみてください。

ControlNetの詳しい使い方については、以下の記事で解説しています。

拡張機能について

拡張機能を追加することで、さまざまなことが出来るようになります。
例えば、次のことができます。
・手や顔を修正できる
・ポーズを作成してポーズ通りに画像生成することができる
・Stable Diffusion Web UIを日本語化できる
・背景を透過させた画像を生成できる
・AI動画を生成できる
上記は一部であり、他にも多くのことができます。
拡張機能は「Extensions」の項目から
目的に合ったファイルをインストールして使用できます。
非常に便利な機能が多くあるので是非導入してみてください。
使えるおすすめの拡張機能について、以下の記事で紹介しているので読んでみてください。

Restore faces(顔を綺麗にする)

「Restore faces」は、Generative Facial Prior GAN(GFPGAN)とも呼ばれる技術を使用しています。
「GFPGAN」は、顔の形や表情の特徴を学習しており
生成画像の品質を向上させるために使用されています。
使い方についてですが
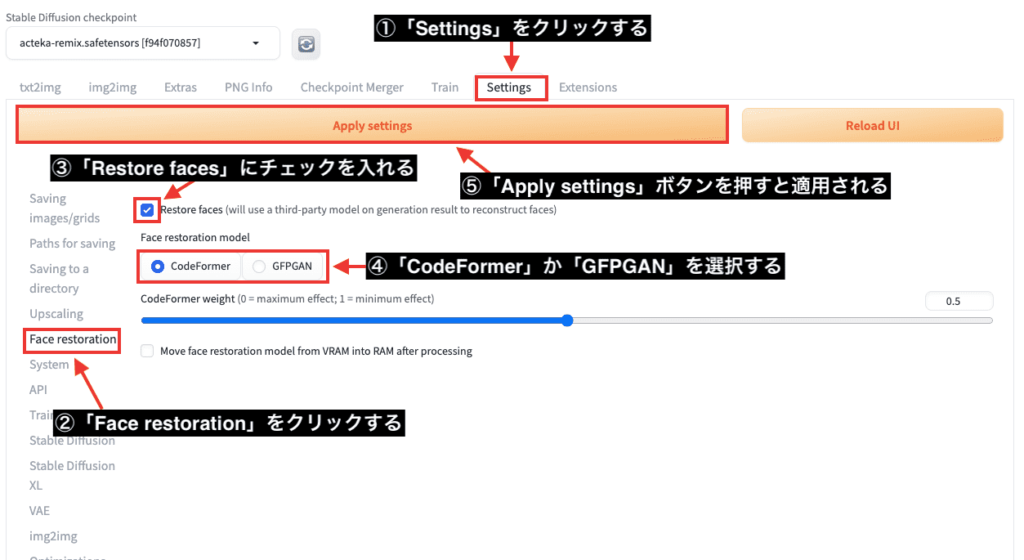
Stable Diffusion Web UIがV1.6に変わってから「Restore faces」の設定場所が変わりました。
以下の画像にある順番に沿って操作すると使用できます。
①「Settings」をクリックする
②「Face restoration」をクリックする
③「Restore faces」にチェックを入れる
④「CodeFormer」か「GFPGAN」を選択する
⑤「Apply settings」ボタンを押すと適用されます
以下の画像は、「Restore faces無し」「CodeFormer」「GFPGAN」を比較した結果になります。
「CodeFormer」では、髪や口付近など全体に汚れが目立ちクオリティが低くなりました。

「無し」と「GFPGAN」では、何が変わっているのか少し分かりずらいので動画にしました。
「無し」と「GFPGAN」を比べると、同じようなクオリティで全体が少しだけ修正されていました。
画像生成して顔が崩れやすい場合に
「Restore faces」を使用して画像生成することで
バランスを整えて補正してくれる場合があります。
「Restore faces」は
リアル風では良くなりやすいのですが
アニメ風では逆に顔が崩れてクオリティを落としやすい傾向にあるので
どちらも画像生成して比較してから良い方を選択するといいでしょう。
まとめ

以上で、Stable Difffusion Web UI(AUTOMATIC1111)の使い方について解説しました。
各設定項目に詳しくなることで
クオリティの高いAIイラストを生成することができます。
モデルによって品質が上がる設定などが違ってくるので
試行錯誤して自分なりの設定方法を見つけましょう。
顔・目の部分が崩れてしまう人は
以下の記事を読むと解決できるので是非読んでみてください。


